window本地部署DeepSeek详细教程
为何要本地部署
不用联网,有数据隐私方面担忧的或者保密单位根本就不能上网。
部署流程
版本选择
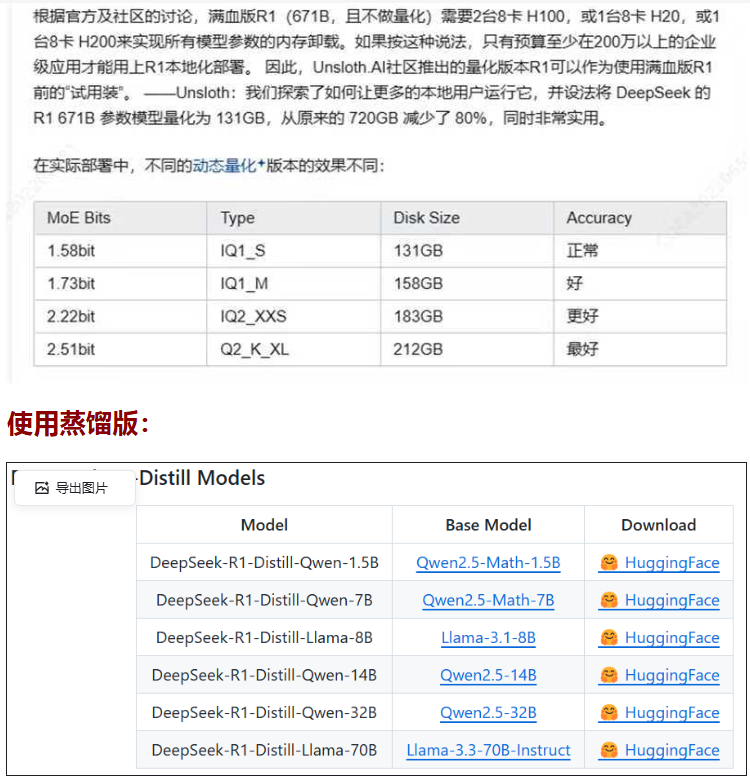
蒸馏版本:https://huggingface.co/deepseek-ai
开源2+6个模型。R1预览版和正式版的参数高达660B,非一般公司能用。为进一步平权,于是他们就蒸馏出了6个小模型,并开源给社区。最小的为1.5B参数,10G显存可跑。
如果你要在个人电脑上部署,一般选择其他架构的蒸馏模型,本质是微调后的Llama或Qwen模型,基本32B以下,并不能完全发挥出DeepSeek R1的实力。
下载安装Ollama
接着傻瓜式安装:
安装完后,验证是否安装成功,在终端中输入如下命令:
ollama -v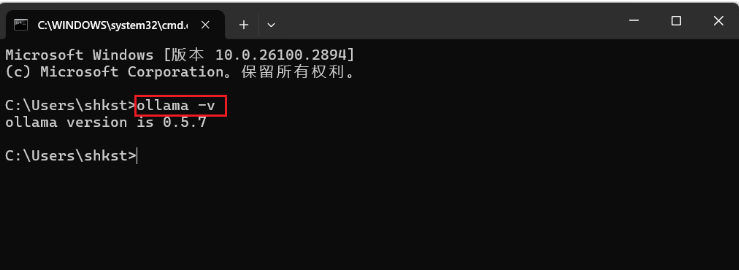
能显示ollama版本说明安装成功
选择r1模型
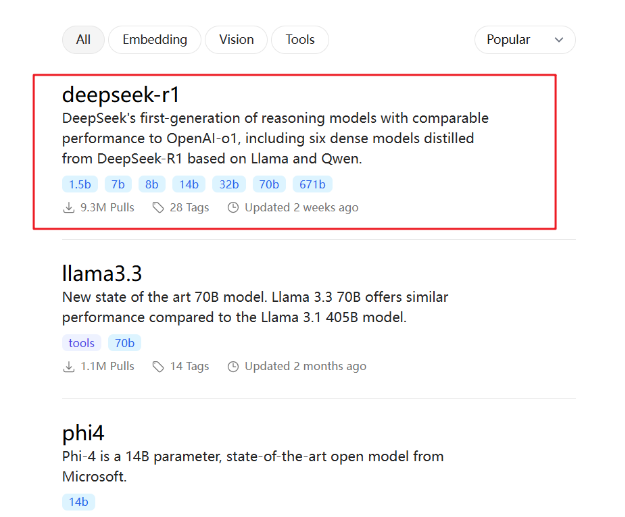
选择版本:
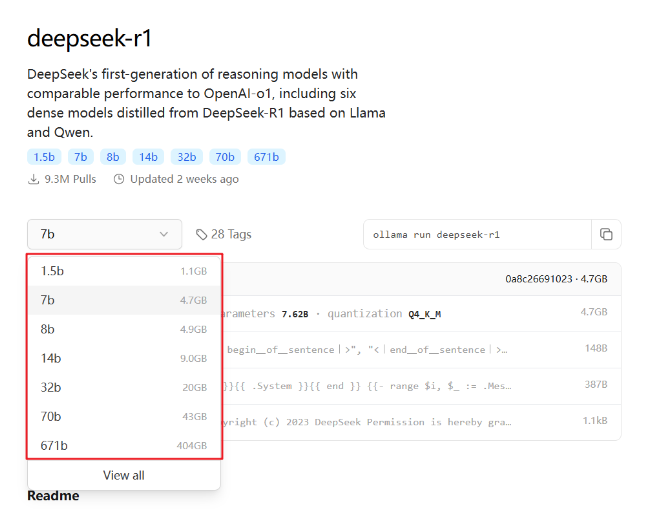
b代表10亿参数量,7b就是70亿参数量。这里的671B是HuggingFace经过4-bit 标准量化的,所以大小是404GB。
ollama 支持 CPU 与 GPU 混合推理。将内存与显存之和大致视为系统的 “总内存空间”。如果你想运行404GB的671B,建议你的内存+显存能达到500GB以上。
除了模型参数占用的内存+显存空间(比如671B的404GB)以外,实际运行时还需额外预留一些内存(显存)空间用于上下文缓存。预留的空间越大,支持的上下文窗口也越大。所以根据你个人电脑的配置,评估你选择部署哪一个版本。如果你想运行404GB的671B,建议你的内存+显存能达到500GB以上
这里我们以7B为例,大多数的电脑都能够运行起来。
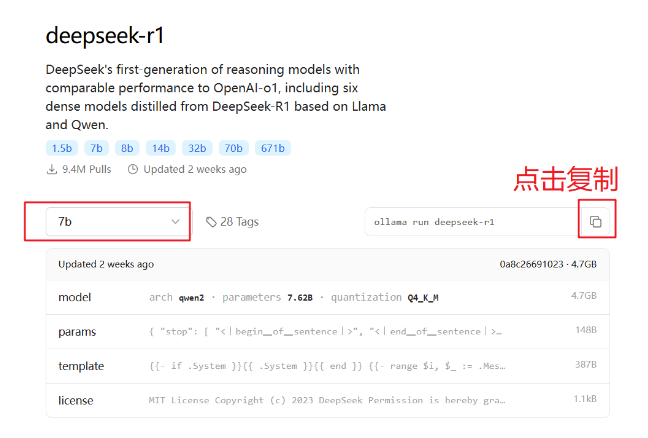
本地运行DeepSeek模型
在命令行中,输入如下命令:
ollama run deepseek-r1:7b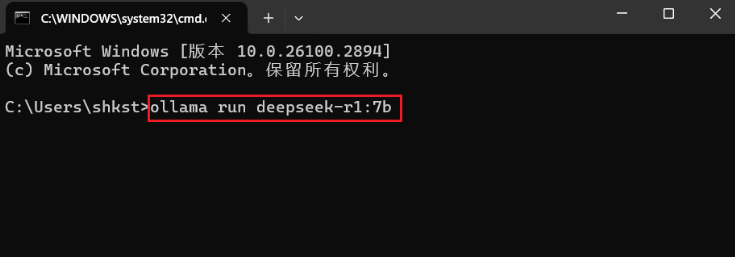 首次运行会下载对应模型文件:
首次运行会下载对应模型文件:
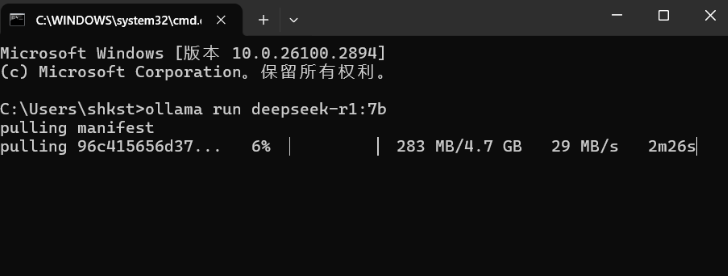
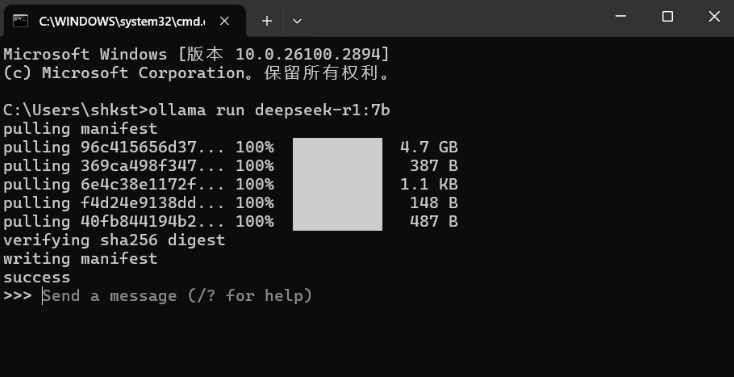
下载支持断点续传,如果下载中速度变慢,可以鼠标点击命令行窗口,然后ctrl+c取消,取消后按方向键“上”,可以找到上一条命令,即”ollama run deepseek-r1:7b“,按下回车会重新链接,按照之前进度接着下载。
如果不想下载,也可以直接使用我们提供的下载好的模型文件,按照后续小节 “修改models文件夹路径” 的步骤配置好环境变量和对应models文件夹的路径即可。
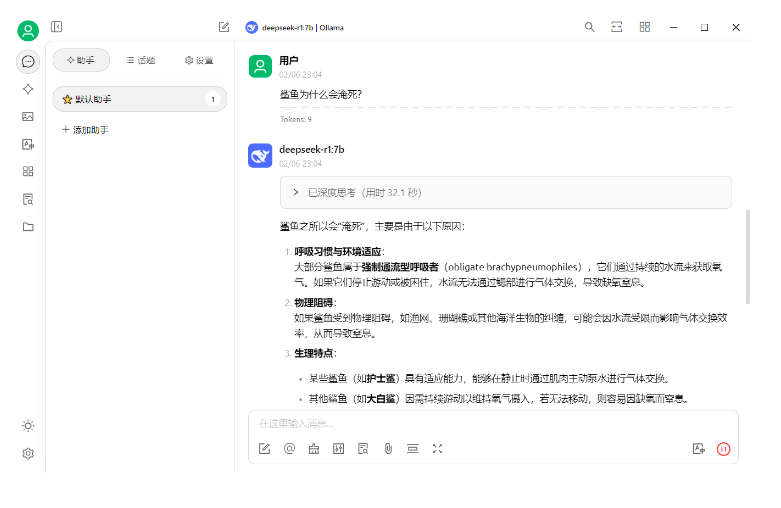
下载完成后,自动进入模型,直接在命令行输入问题,即可得到回复。比如:打个招呼!
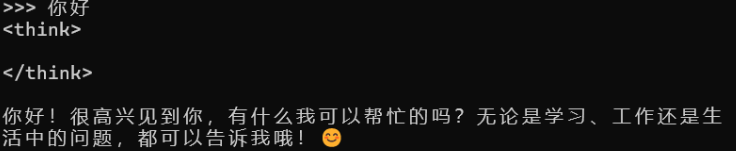
常用几个命令
获取帮助:
/?退出对话:
/bye查看已有模型:
ollama list使用客户端工具
本地部署好模型之后,在命令行操作还是不太方便,我们继续使用一些客户端工具来使用。
Cherry Studio的下载
Cherry Studio的下载地址:https://cherry-ai.com
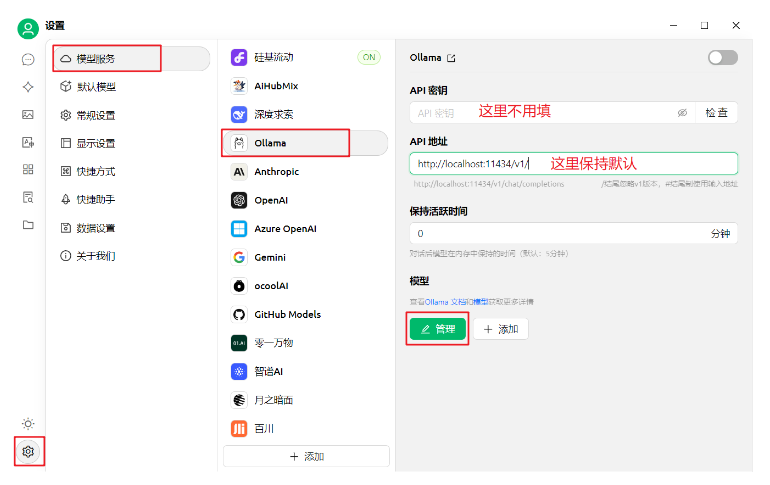
Cherry Studio的使用
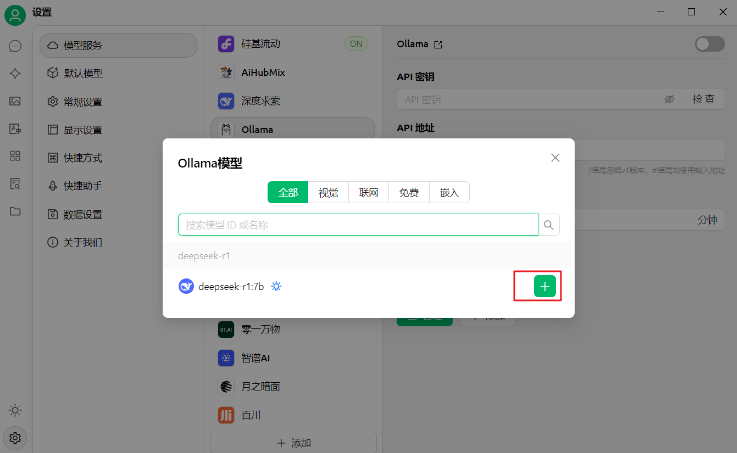
如果这里列表没有r1模型,则是之前没有安装好。
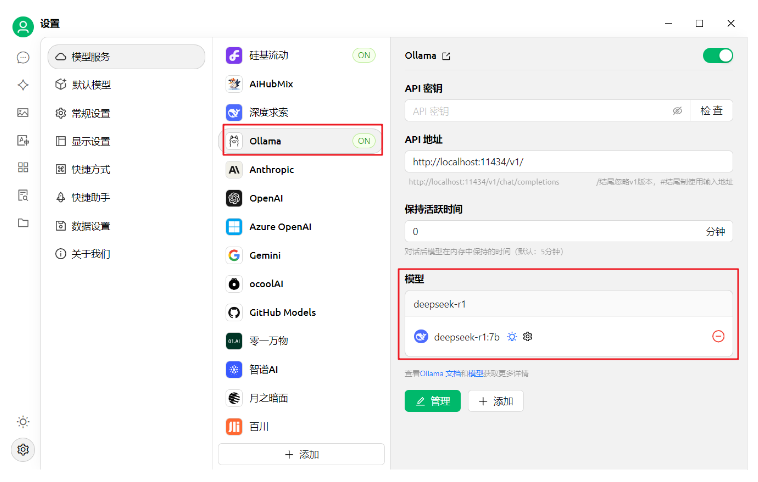
选择模型
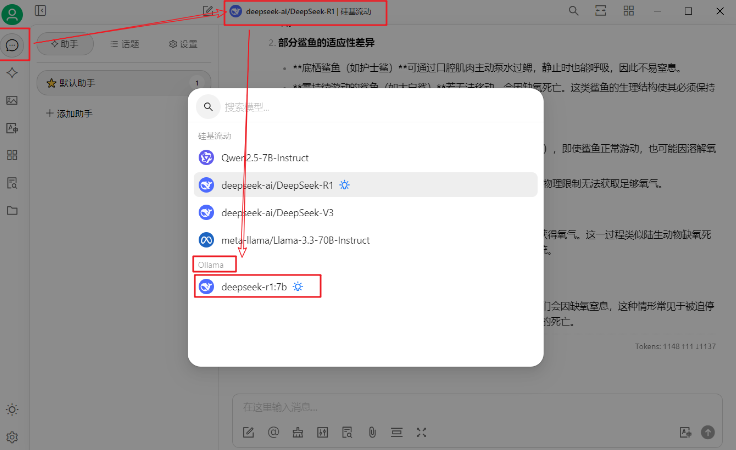
注意:使用时要确保ollama客户端已启动
修改models文件夹路径
模型默认会下载到: C:\Users\你的用户名.ollama 目录下的models文件夹
如果想修改模型的存放位置,做如下配置:
步骤1:拷贝models文件夹到你指定的目录,比如我剪切到E:\ollama 下
步骤2:添加环境变量。右键“我的电脑”,选择“属性”,按如下方式配置:
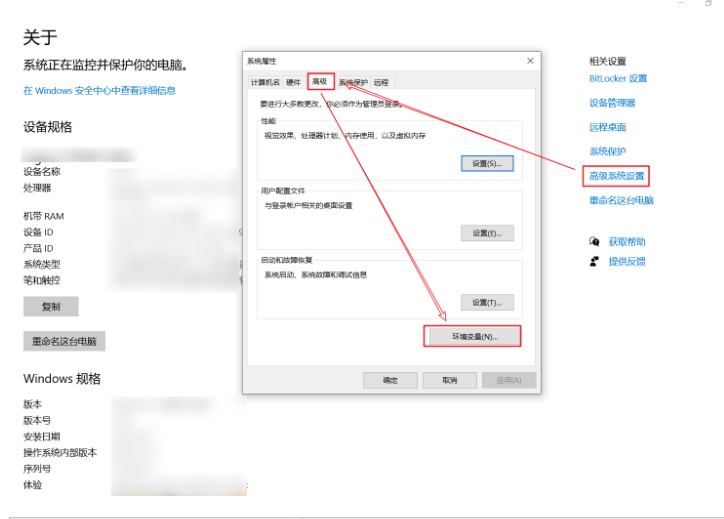
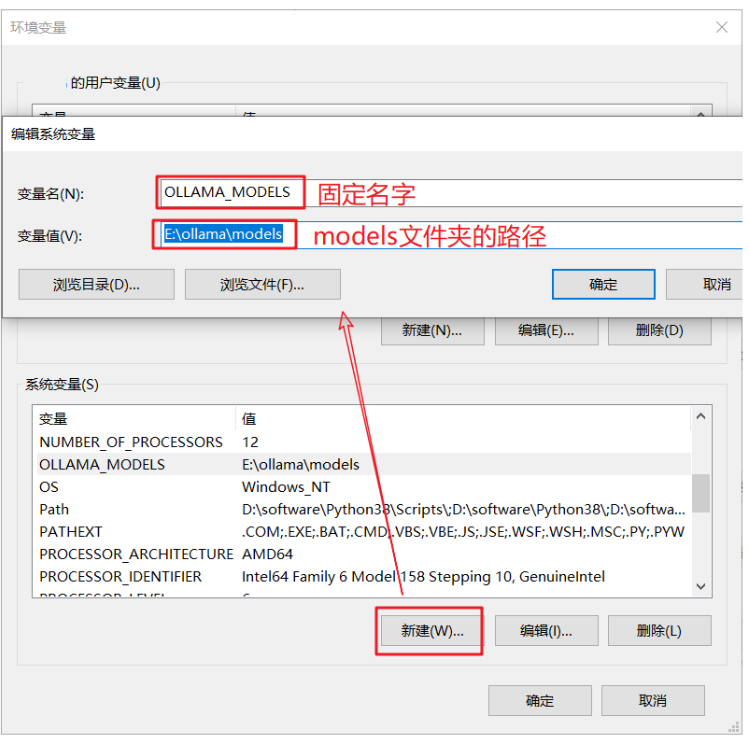
步骤3:重启Ollama客户端生效
注意:修改完之后,需要重启Ollama客户端,右键图标,选择退出,重新运行Ollama
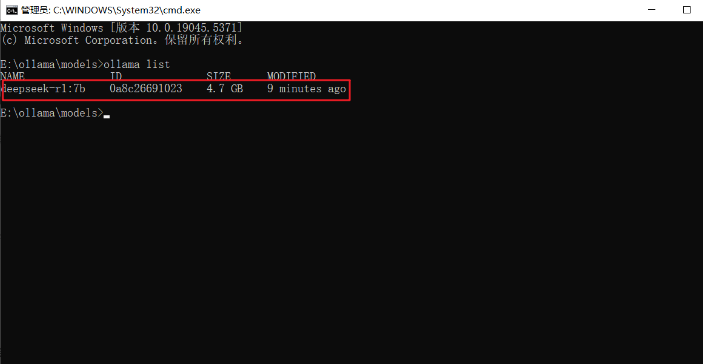
验证是否生效:重新运行Ollama之后,重新打开命令行,输入命令 ollama list 查看:
如果list显示为空,则表示操作有问题,确认以上步骤。
服务器部署
想要私有化部署满血版DeepSeek-R1,即671B版本,需要有更好的硬件配置。服务器可以是物理机,也可以是云服务器。
使用Ollama提供的经过量化压缩的671B模型的大小是404GB,建议内存 + 显存 ≥ 500 GB,举例几种性价比配置如下:
- Mac Studio:配备大容量高带宽的统一内存(比如 X 上的@awnihannun 使用了两台 192 GB 内存的 Mac Studio 运行 3-bit量化的版本)
- 高内存带宽的服务器:比如 HuggingFace 上的 alain401 使用了配备了 24×16 GB DDR5 4800 内存的服务器)
- 云 GPU 服务器:配备 2 张或更多的 80GB 显存 GPU(如英伟达的 H100,租赁价格约 2 美元 / 小时 / 卡) 在这些硬件上的运行速度可达到 10+ token / 秒。
部署流程与个人电脑部署7B的流程没有太大区别,都是以下几个步骤:
- 根据服务器的操作系统,下载对应版本的Ollama客户端;
- 运行Ollama,执行 Ollama命令 运行 671B版本模型;首次执行自动下载模型;
- 使用客户端工具/自己开发页面/代码调用,对接Ollama的R1模型;